Chest X-Ray Generative Adversarial Network
A common problem in machine learning is obtaining enough data to train your model. In cases of too few samples, the model does not have enough chances to learn the correct features to generalize well on out-of-sample data. Of course, it is important that the data we train a model on should be of appropriate quality, as bad data in equals bad data out.
This project aims to create a general adversarial network (GAN) that can generate unique chest radiograph, or x-ray images. Successful results enable the use of an additional method of image *data augmentation* on top of existing techniques, including skewing, rotation, and flipping. If a model does not suffer from high bias, then training on additional, high-quality, generated data can allow it to better learn and generalize.
Here we create GAN to generate any number of desired images. Then, we feed these images into a image segmentation model to train.
Code
Here is the project's code.
Data
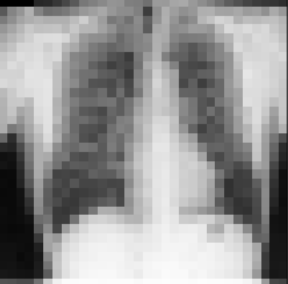
The original chest radiograph dataset is provided by the Japan Radiological Society (JRS), but is also available on Kaggle. It consists of 247 grayscale images of 1024 x 1024 pixels in size. This is quite a miniature dataset, but it will suite the purpose of training a simple GAN that generate discernable chest x-ray images. To simplify the memory footprint for training, images are resized to 256x256 and have their pixel values normalized.
A resized chest radiograph image (256x256):
Model
A GAN is composed of a generator and a discriminator. The generator is responsible for generating what it believes are real images. To break it down simply, a generator has the following properties.
Generator
- Input: Random noise (vector of random numbers sampled from normal distribution)
- Output: Generated image that tries to look like a real image
The generator is a neural network that iteratively adjusts its weights to generate a more authentic image to reduce loss presented by the discriminator.
The discriminator's job is to classify whether the generator's output is a real or fake image.
Discriminator
- Input: Takes in real data from training dataset, and fake data produced by the generator
- Output: A prediction probability for whether output is real or not (binary classification)
The discriminator is a neural network that trains to best discern between fake and real images. Thus, the generator and discriminator are in an adversarial relationship, with the generator trying to best fool the discriminator, and the discriminator trying to catch the generator's fake images.
Training Process
- Sample batch of real data from training set
- Use generator to make batch of fake data, using random noise as input
noise = torch.randn(batch_size, latent_dim) fake_images = G(noise) - Train discriminator to discern fake & real images
real_preds = D(real_images) fake_preds = D(fake_images) real_loss = loss_fn(real_preds, real_labels) fake_loss = loss_fn(fake_preds, fake_labels) -
Train generator to fool discriminator. We provide the generator with all real labels (1's) to make it minimize the loss to make it learn to generate more real images that are more real.
labels_for_generator = [1] * n fake_preds = D(fake_images) generator_loss = loss_fn(fake_preds, labels_for_generator)Over iterations, we see that if the discriminator's fake_preds are closer to real, the generator loss decreases...a good sign!
- Repeat
There are two seperate loss functions, one each for the generator and discriminator.
Results
Below shows some generated images as more time passes for the generator to learn. Observe how the images start as random noise and become more real.

Conclusion
Within the scope of our goals, it appears that the generator was able to successfully generate quite realistic chest x-rays. Going forward, we can incorporate these generated images as part of data augmentation to improve model training.